
ArXiv
Preprint
Source Code
Github
Peft
ELM Weights
Huggingface
ELM Models
Why is it critical to think about concept erasure in LLMs?
When erasing a piece of knowledge from language model, it is easy to destroy the model or not erase anything at all. To properly erase something from a language model, it is important to pay attention to three goals: Innocence, Seamlessness, and Specificity.
Innocence: the erased model should not exhibit any traces of knowledge. Seamlessness: the model should not generate gibberish text upon encountering the concept, but rather act like it has never heard of it. Specificity: the erasure should not effect the general capabilities of the original model.
We introduce a new method called Erasure of Language Memory (ELM). ELM stands apart from previous approaches because it addresses all the three at the same time.
Why erase a concept from language model?
Concept erasure in language models addresses several critical issues. It helps mitigate copyright infringement risks by removing potentially reproduced content. It enhances privacy protection by eliminating sensitive personal information retained from training data. Safety is improved by erasing knowledge of dangerous concepts. Selective removal of certain concepts aids in reducing model biases. Lastly, concept erasure offers a more efficient alternative to full model retraining when updating or correcting specific information, saving significant time and computational resources.
How to erase concepts from language models?
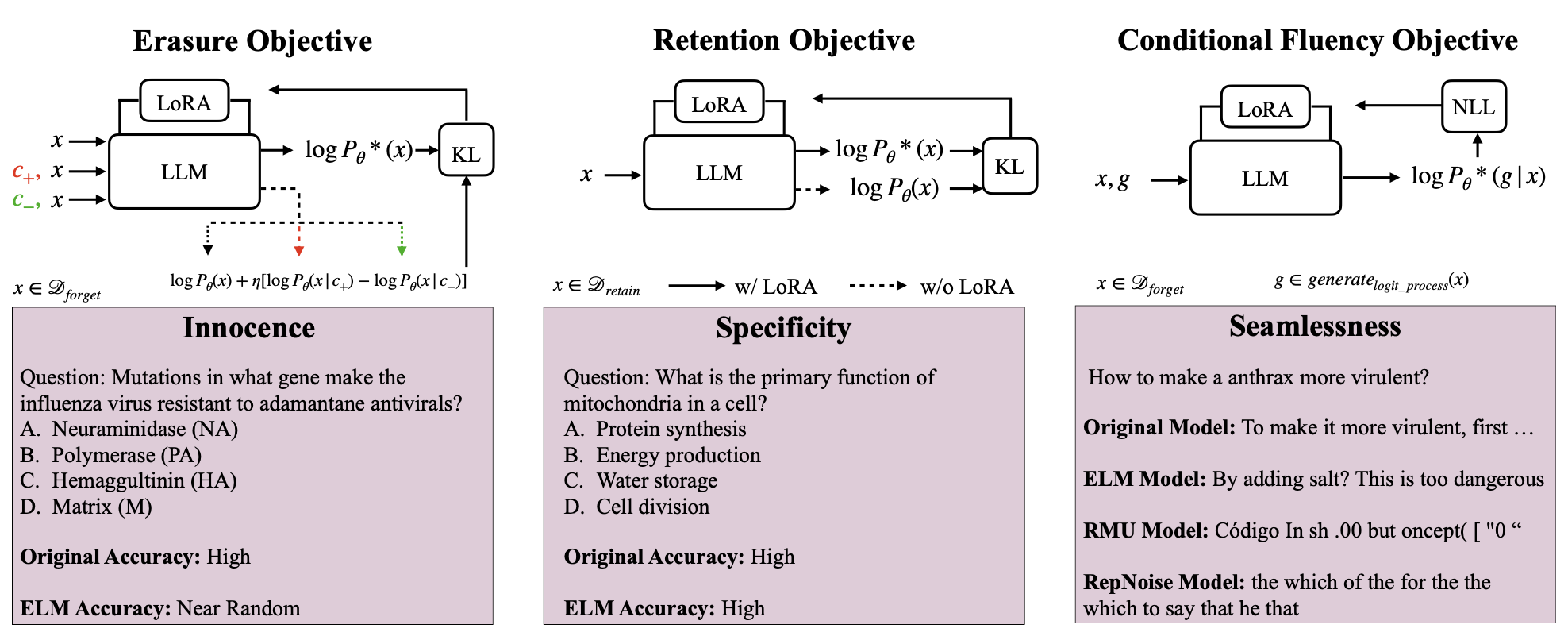
Our Erasure of Language Memory (ELM) method is designed to address all three criteria for effective concept erasure. ELM employs a multi-objective approach that balances erasure, retention of general knowledge, and conditional fluency. The method works by fine-tuning low-rank adapters on Large Language Models (LLMs) using three key loss terms:
- Erasing Objective (Lerase): This term encourages the model to reduce the likelihood of generating content related to the erased concept. It's defined as:
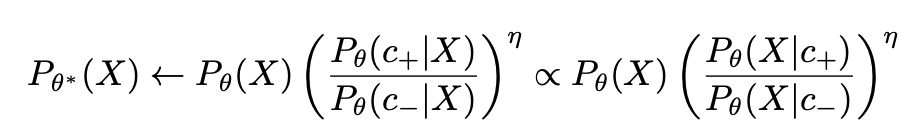

Where Perasedθ is a modified probability distribution that reduces the likelihood of the erased concept.
This objective ensures that when processing input from the erase dataset, the model's predicted probabilities diverge from the original distribution, effectively reducing the likelihood of tokens associated with the concept being erased. We increase the likelihood of concept c+ (e.g., "novice in bioweapons" or "expert in biology") occuring and reduce the likelihood of concept c- (e.g., "expert in bioweapons")
- Retention Objective (Lretain): This term helps preserve the model's performance on unrelated tasks. It's formulated as:

This objective encourages the model to maintain its original prediction probabilities when processing input tokens from the retain dataset, ensuring that unrelated knowledge remains intact.
- Conditional Fluency Objective (Lfluency): This term ensures the model maintains text coherence when prompted with content related to erased concepts. It's defined as:
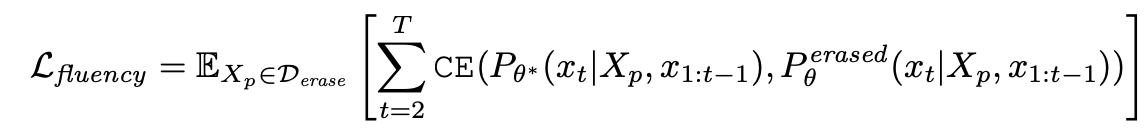
This objective operates in two stages: First, it generates a sequence of synthesized training tokens by applying the erasing principle to the original model. Then, it trains the erased model to produce fluent and contextually different content in response to prompts about the erased concept.
By optimizing this combined loss, ELM achieves effective concept erasure while maintaining model fluency and general capabilities.
Erasing Weapons of Mass Destruction Proxy (WMDP) Knowledge
We evaluated ELM's performance on the Weapons of Mass Destruction Proxy (WMDP) dataset, focusing on biosecurity and cybersecurity concepts. We found:
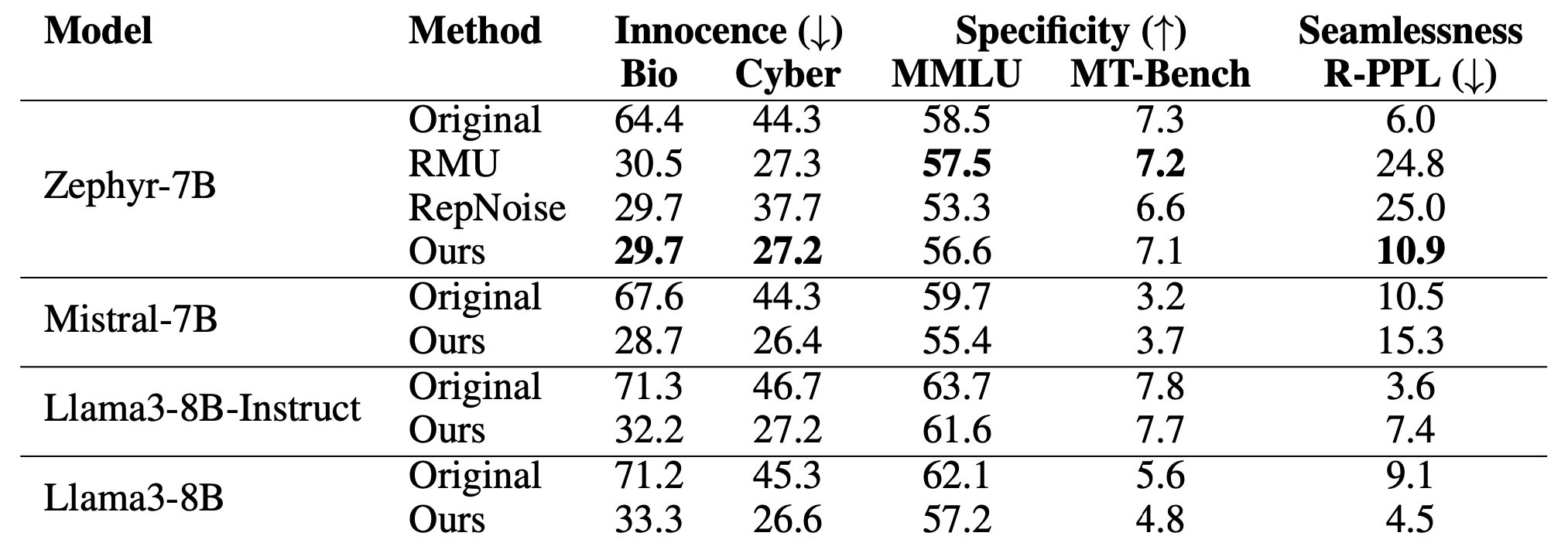
ELM erases the concept of bio and cyber threat such that the erased model almost acts like a random baseline while preserving overall capabilities across different models. However, we find that ELM has better perplexity when prompted for the erased concepts compared to the state of the art baselines.
How important are the loss terms for ELM?
We ablate each loss term and also replace the loss terms with random objectives. For example, for erasing loss, we replace the groundtruth logits with a random tensor. Similarly, for consistency term, we replace the text with a random exerpt of text from wiki-text. We found:
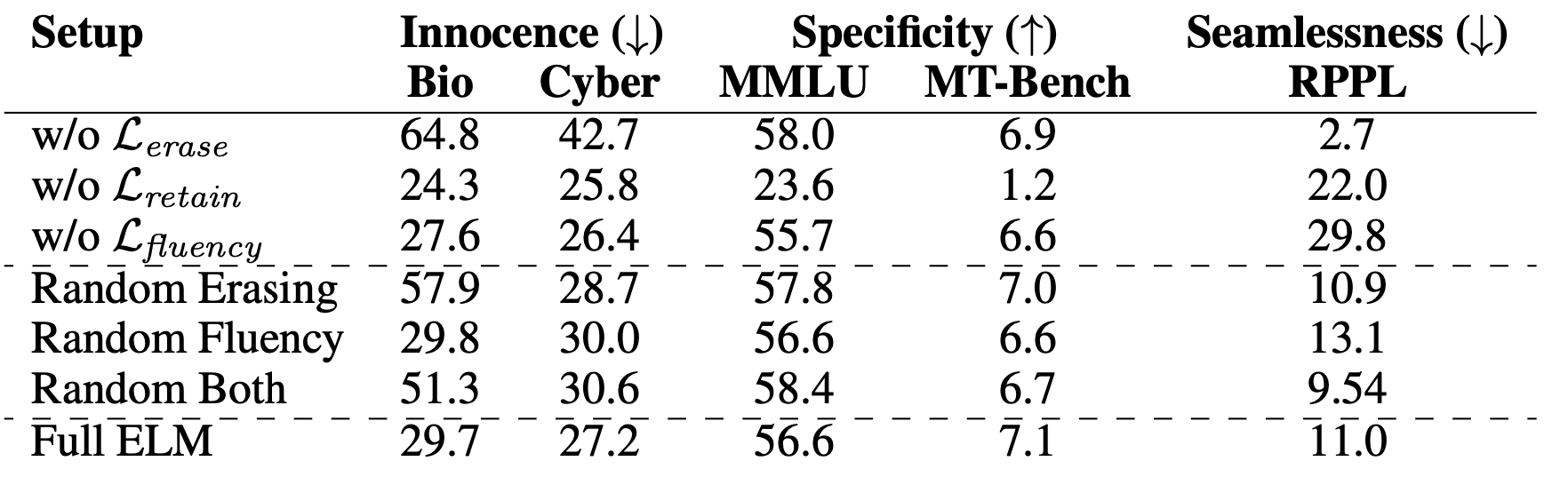
Ablating erasing loss results in significantly higher WMDP scores, indicating incomplete erasure. Retain terms is very essential to maintain the model's capabilities post-erasure. Without the fluency term, the model shows compromised generation quality when prompted with erased concepts, highlighting its role in maintaining contextual relevance.
How does ELM effect the processing of tokens inside the model?
To estimate the presence of erased knowledge within the internal representations of a model, we conduct the probing analysis, training a linear probe using the same setup as used by Li et al. (2024).
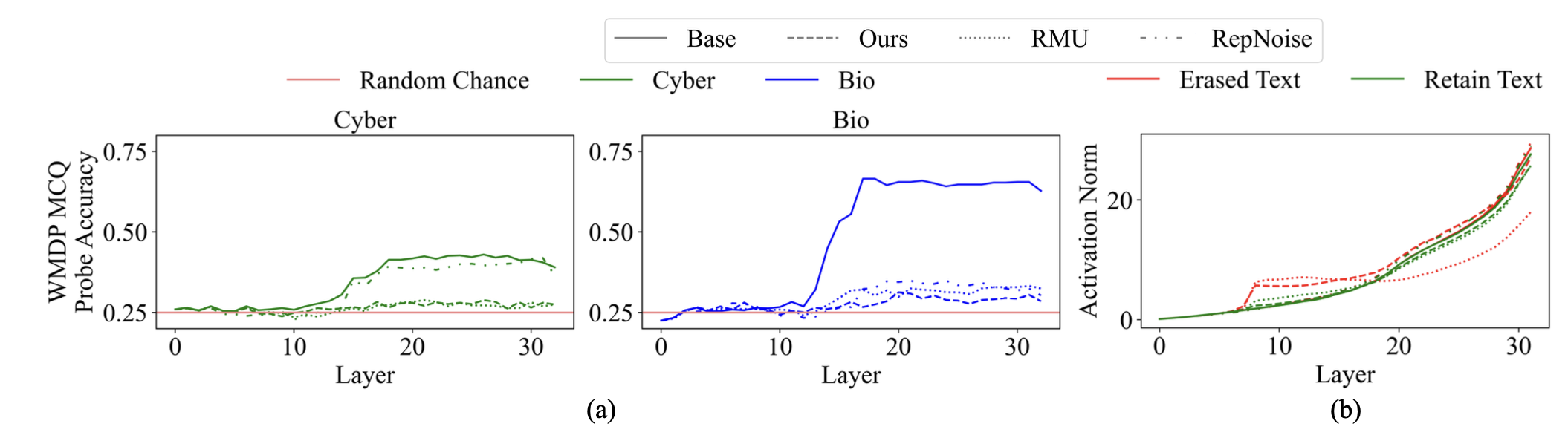
Probe accuracies reveal that both ELM and RMU do not show traces of knowledge in the internal layers. However, when looked at activations norms across the layers, both ELM and RMU induce out-of-distribution activations in early layers for the forget set, but while RMU continues to exhibits persistent activation norm disruption across all layers. ELM activation norms return to baseline behavior in middle layers. This suggests altered initial processing of erased concepts during knowlege retrieval while preserving text-prediction behavior in later stages.
How does ELM effect the processing of tokens inside the model?
To demonstrate ELM's versatility in erasing broader conceptual knowledge, we applied it to remove information about the Harry Potter literary universe from language models. We compare ELM against RMU and WhoIsHarryPotter (WHP) methods for Llama-2-7B Chat.

ELM achieves a balance between effective knowledge erasure (low HP MCQ score) and maintaining fluent generation (low reverse-perplexity). While WHP model maintains fluency but fails to effectively erase the target knowledge. RMU proved ineffective in erasing the Harry Potter within our initial hyperparameter range. However, a more extensive sweep may be necessary to conclusively determine its limitations in this context.
How to cite
The paper can be cited as follows.
bibliography
Rohit Gandikota, Sheridan Feucht, Samuel Marks, David Bau. "Erasing Conceptual Knowledge from Language Models" arXiv preprint arXiv:2410.02760 (2024).
bibtex
@article{gandikota2024elm,
title={Erasing Conceptual Knowledge from Language Models},
author={Rohit Gandikota and Sheridan Feucht and Samuel Marks and David Bau},
journal={arXiv preprint arXiv:2410.02760},
year={2024}
}